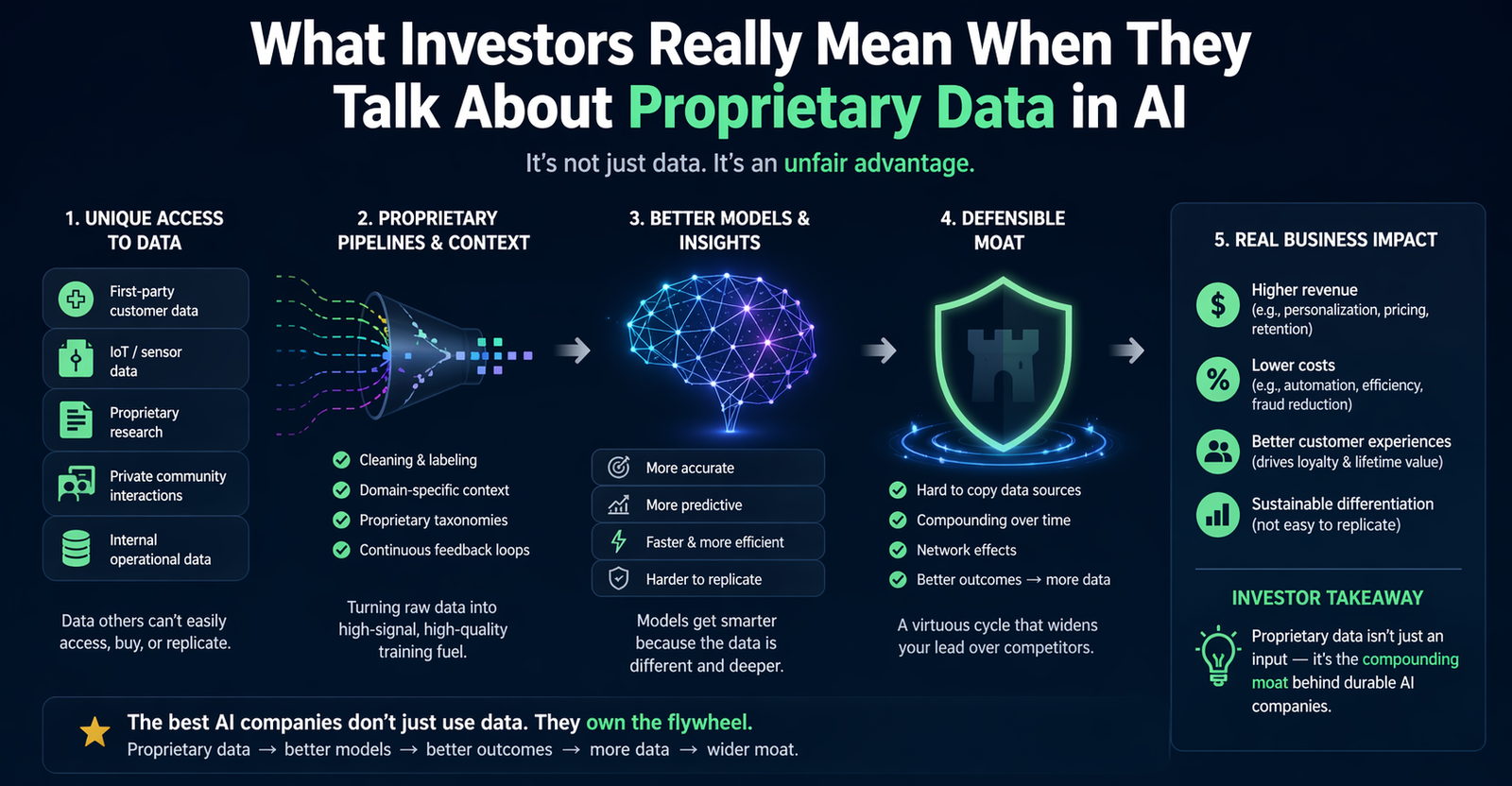
When investors talk about proprietary data in AI, they usually do not mean “we have a private spreadsheet no one else can see.” They mean something much more useful and much harder to copy. In TechCrunch’s January 2025 survey of 20 venture investors focused on enterprise startups, more than half said the strongest edge for an AI startup is the quality or rarity of its proprietary data. But the same piece also shows that investors are really looking for a combination of differentiated data, technical innovation, strong user experience, workflow depth, and customer understanding.
That distinction matters because a lot of founders hear the phrase and reduce it to one idea: own unique data. Investors are usually thinking more broadly. They want to know whether your company has a defensible source of insight that improves the product over time and gets stronger as customers use it. In practice, that often means proprietary data plus a tight feedback loop, strong integrations, and a workflow customers rely on every day. Battery Ventures’ Jason Mendel told TechCrunch he looks for “deep data and workflow moats,” not just one or the other.
Proprietary data is really about defensibility
The easiest way to understand investor thinking is to treat proprietary data as shorthand for defensibility. Investors know that the barrier to launching an AI product is much lower than it used to be. Built In says VCs are no longer impressed by a simple GPT wrapper or a flashy demo. They want traction, repeatability, and evidence that a business cannot be easily replicated. The question behind all of this is simple: why can’t another startup build something very similar next month?
That is why the best founders do not talk about data as a static asset. They talk about what that data enables. Can it improve model performance in a specific domain? Can it make your output more accurate, more useful, or more trusted than a general-purpose model? Can it help the product learn from real usage in a way a competitor cannot easily match? Those are the answers investors are usually hunting for, even when they use the simpler phrase “proprietary data.”
It is not just the data. It is what you do with it
One of the most important lines in the TechCrunch article comes from Work-Bench’s Jonathan Lehr, who says it is not only about the data a company has, but also how it can clean that data up and put it to work. That is a much sharper way of thinking about the problem. A messy pile of private information is not a moat by itself. What matters is whether the company can turn raw inputs into a better product, a smarter workflow, or a more reliable system.
This is why investors often care so much about the operational side of data. Startups that can collect, label, clean, structure, and use domain-specific data in a repeatable way tend to look much stronger than startups that simply claim to have access to something “exclusive.” The defensible part is often the system around the data, not just the data alone.
Vertical AI makes the point even clearer
The idea becomes much easier to see in vertical AI. Norwest Venture Partners’ Scott Beechuk told TechCrunch that hard-to-get data becomes increasingly important for startups building vertical solutions. Intel Ignite makes a similar point from a slightly different angle, saying startups become more valuable and profitable when they pair AI technology with proprietary or semi-proprietary data, especially in areas like healthcare and financial services.
Why do investors care so much about this in vertical markets? Because in specialized industries, generic models usually are not enough. The winner is often the company that understands a specific workflow, has access to better signals, and can use that knowledge to solve a real operational problem. That is a stronger story than “we built another AI tool on top of a foundation model.” It shows why the company might deserve a long-term position in the market.
Investors also mean feedback loops
Another theme investors keep coming back to is the feedback loop. Databricks Ventures’ Andrew Ferguson told TechCrunch that rich customer data, especially data that creates a feedback loop in an AI system, can make a startup more effective and help it stand out. That matters because investors are not just looking for a snapshot advantage. They want a compounding advantage.
A feedback loop tells investors that the product can improve with use. That is much more powerful than a one-time dataset. If every customer interaction helps the company refine output quality, improve recommendations, or better fit a real workflow, the startup begins to look harder to displace. In investor terms, that starts to sound like a real moat instead of a temporary lead.
Proprietary data alone will not save a weak company
This is the part founders sometimes miss. Investors are not saying proprietary data is the only thing that matters. TechCrunch also found that VCs care about strong talent, existing integrations, and deep understanding of customer workflows. Built In adds that VCs now want proof of traction, superior execution, top-tier AI talent, and a business that is ethical, transparent, and regulation-ready.
So if a founder says, “we have proprietary data,” but cannot explain customer demand, repeatability, team quality, or why the product fits into real work, the claim will not land the way they hope. Investors are using proprietary data as one signal of defensibility, not as a substitute for the rest of the business. The strongest companies combine data advantage with distribution, execution, and product relevance.
What investors actually want founders to prove
A better way to think about the investor question is this: what do you own, control, or understand that others cannot easily reproduce? Sometimes that really is exclusive data. Sometimes it is a privileged position inside a workflow. Sometimes it is a better labeling process, stronger integrations, deep domain expertise, or a product that learns from usage in ways competitors cannot match. Built In says VCs want founders to explain their unique value proposition, differentiation, and moat, including whether their data is proprietary, whether it is differentiated from general-purpose LLMs, and whether they have exclusive partnerships or deep domain expertise.
That is why the phrase keeps coming up in AI funding conversations. Investors know that models are becoming more accessible, and product features can be copied quickly. What they really want is proof that your company gets stronger as the market gets noisier. If the answer is yes, then the startup starts to look fundable for the right reasons.In the end, when investors talk about proprietary data in AI, they are usually talking about a durable edge. Not a buzzword. Not a pitch-deck shortcut. A durable edge that helps the company build better products, fit deeper into customer workflows, and stay harder to replace as the market fills up. That is what the phrase means when investors are using it seriously.